Abstract
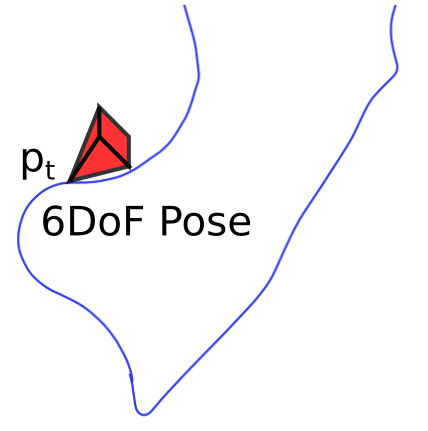
Mobile robots operating in unknown urban environments encounter a wide range of complex terrains to which they must adapt their planned trajectory for safe and efficient navigation. Most existing approaches utilize supervised learning to classify terrains from either an exteroceptive or a proprioceptive sensor modality. However, this requires a tremendous amount of manual labeling effort for each newly encountered terrain as well as for variations of terrains caused by changing environmental conditions. In this work, we propose a novel terrain classification framework leveraging an unsupervised proprioceptive classifier that learns from vehicle-terrain interaction sounds to self-supervise an exteroceptive classifier for pixel-wise semantic segmentation of images. To this end, we first learn a discriminative embedding space for vehicle-terrain interaction sounds from triplets of audio clips formed using visual features of the corresponding terrain patches and cluster the resulting embeddings. We subsequently use these clusters to label the visual terrain patches by projecting the traversed tracks of the robot into the camera images. Finally, we use the sparsely labeled images to train our semantic segmentation network in a weakly supervised manner. We present extensive quantitative and qualitative results that demonstrate that our proprioceptive terrain classifier exceeds the state-of-the-art among unsupervised methods and our self-supervised exteroceptive semantic segmentation model achieves a comparable performance to supervised learning with manually labeled data.